Inteligência Artificial
22 de outubro de 2025
A importância da organização dos dados na era da IA
Porque qualidade e contexto dos dados são um fator diferencial competitivo na era da IA

Hoje, a inteligência artificial ocupa o centro das conversas estratégicas nas organizações. Mais do que uma percepção individual, sua presença constante em eventos, treinamentos e reuniões corporativas é confirmada por dados. O Artificial Intelligence Index Report 2025, publicado pela Universidade de Stanford — considerado o mais confiável e abrangente relatório sobre IA no mundo — confirma o aumento expressivo da relevância do tema. Em sua 8ª edição, o documento mostra que a adoção da tecnologia cresceu de forma acelerada, e os investimentos privados ultrapassaram a marca de 252 bilhões de dólares globalmente. A inteligência artificial deixou de ser um recurso experimental para se tornar parte estrutural das decisões, dos produtos e das estratégias.
Esse avanço fica evidente no gráfico a seguir, que mostra que 78% das organizações já utilizam IA em pelo menos uma função, enquanto 71% adotaram soluções de IA generativa. O salto entre 2023 e 2024 evidencia a aceleração da adoção dessas tecnologias, que, além de automatizar processos, agora interagem de forma natural e criam.
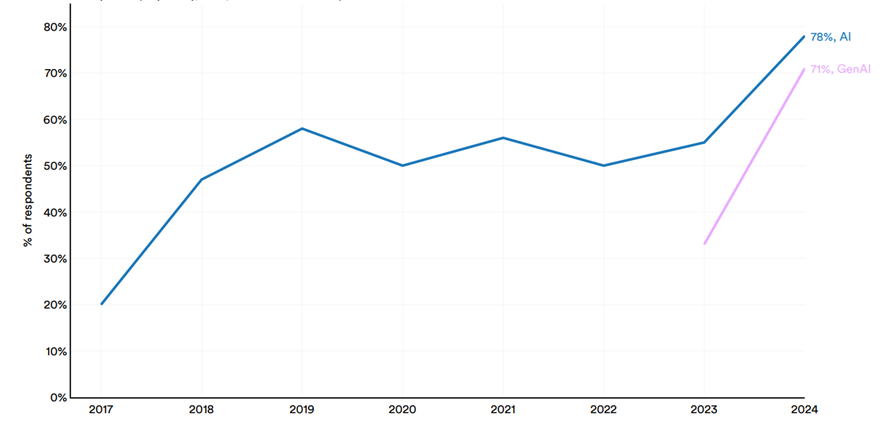
Fonte: McKinsey & Company Survey, 2024.
Apesar da popularidade do tema, muitas empresas ainda não estão preparando seus ambientes internos para extrair o melhor da tecnologia. Olhar para esse cenário com pragmatismo, investindo em estrutura, organização e clareza sobre os dados que alimentam os modelos, pode representar um diferencial competitivo real nos próximos anos. É essencial desenvolver letramento em IA: compreender os fundamentos da tecnologia para participar das decisões com criticidade. Este texto não busca cobrir todos os aspectos da inteligência artificial, mas se concentra em uma etapa muitas vezes negligenciada: a qualidade dos inputs, especialmente dos dados.
De forma simplificada, modelos de IA são algoritmos estatísticos que processam probabilidades com base em grandes volumes de dados. No caso dos LLMs (Large Language Models), como os que estão por trás de ferramentas populares como o ChatGPT ou o Gemini, estamos falando de bilhões — ou até trilhões — de parâmetros alimentados por bases massivas. Compreender essa escala é desafiador: um modelo de 8 bilhões de parâmetros é considerado pequeno, enquanto o DeepSeek, com 80 bilhões, já é classificado como grande (e há modelos muito maiores).
Mas modelos maiores não significam necessariamente modelos melhores. O tamanho está ligado à capacidade de cobrir mais contextos, não à qualidade intrínseca das respostas. Um modelo treinado com bilhões de dados pode saber tanto sobre receitas quanto sobre programação, mas isso não garante precisão em cada domínio. É justamente aí que reside tanto o potencial quanto o desafio: a qualidade dos dados utilizados define, em última instância, a qualidade das respostas que esses modelos são capazes de entregar.
Imagine treinar um modelo apenas com dados de gastronomia, deixando de fora informações sobre programação. Ele pode se tornar extremamente preciso em receitas, mas incapaz de responder sobre códigos e vice-versa. Essa seletividade revela o que se torna cada vez mais relevante: modelos alimentados com dados contextualizados, curados e estruturados.

Grande parte das chamadas “alucinações” geradas por modelos ocorre justamente pela influência direta dos inputs no resultado. Sam Altman, CEO da OpenAI, afirmou recentemente: “As pessoas têm um grau muito alto de confiança no ChatGPT, o que é interessante, porque a IA tem alucinações. Deveria ser a tecnologia em que você confia menos.” A confiança excessiva, somada à baixa compreensão sobre o funcionamento dos modelos, aumenta o risco de erros estratégicos e decisões baseadas em respostas superficiais.
Muito se fala em engenharia de prompt — a disciplina de formular comandos de texto para obter respostas mais assertivas. Mas, antes do prompt, é a qualidade e a preparação dos dados que determinam a eficiência do modelo. É nesse contexto que ganham força os SLMs (Small Language Models), modelos menores e mais específicos, treinados com bases segmentadas. Em vez de tentar cobrir todos os contextos, são projetados para atuar com profundidade em domínios delimitados.
Lucas de Oliveira e Felipe Silva, especialistas em tecnologia e machine learning, destacam que, além de apresentarem maior acurácia, esses modelos também são energeticamente mais eficientes. Um exemplo é o Phi-3-mini, modelo de 3,8 bilhões de parâmetros que atingiu desempenho equivalente ao PaLM (540B) em testes de MMLU — um salto de eficiência de 142 vezes.
Entretanto, utilizar modelos genéricos, sem treinamento contextual ou base proprietária, aumenta o risco de resultados inconsistentes e até de exposição de informações sensíveis. O simples ato de enviar arquivos, planilhas ou textos confidenciais a ferramentas públicas de IA já representa um risco à privacidade e à segurança dos dados, pois essas informações podem ser incorporadas aos processos de treinamento de grandes modelos.
Falo sobre a importância do letramento em IA porque, quando tratamos do tema, surgem diferentes camadas de discussão. Um termo recorrente nessas conversas é o tuning — ou, de forma simplificada, o treinamento de modelos. Esse processo consiste em fornecer dados para que o modelo aprenda e se adapte a determinado contexto. A quantidade e a qualidade dessas informações influenciam diretamente o resultado: é possível oferecer um volume reduzido de dados e obter um modelo pequeno e especializado, ou trabalhar com uma massa gigantesca e criar modelos amplos e generalistas. Em essência, o treinamento é a forma de organizar e direcionar o comportamento de um modelo para um contexto específico — como o exemplo citado da IA especialista em gastronomia e sem contexto de programação.
Cada organização possui dados únicos sobre suas operações, clientes e mercados. Tratar essas informações de forma sistemática — organizando-as de modo estruturado e padronizado — cria um conjunto de dados equilibrados que facilitam estratégias de uso, seja em modelos estatísticos tradicionais, seja em algoritmos de previsão e inteligências artificiais voltadas à criação de cenários e planos estratégicos.
Esses conjuntos de dados estruturados são chamados de datasets: coleções organizadas de informações prontas para análise. A partir de datasets internos, é possível construir soluções capazes de atuar como agentes de apoio contextualizados, alinhados à realidade e à linguagem de cada negócio. Mais do que um investimento técnico, trata-se de uma mudança cultural: preparar pessoas, processos e fluxos para lidar com dados de maneira estratégica e consciente.
Nesse sentido, documentar bem nunca foi tão importante. Registros de reuniões, atas, rastreabilidade de tarefas e padronização de processos formam uma base de conhecimento que, no futuro, pode alimentar modelos internos de IA com contexto e precisão. Organizações que já possuíam essa cultura têm vantagem: seus dados estão mais equalizados e, portanto, podem ser usados. Já aquelas que não mantinham esse cuidado precisam agir agora — ainda que de forma reativa —, criando o hábito de registrar e organizar desde já. A boa notícia é que as próprias ferramentas de IA podem ajudar nesse processo.
Plataformas de videoconferência já oferecem recursos de transcrição automática; modelos generativos ajudam a aplicar padrões em anotações e relatórios; e outras ferramentas são capazes de resumir grandes volumes de informação. O uso dessas IAs auxilia na preparação de datasets para o treinamento de novos modelos — ou simplesmente fornece contexto adicional para prompts, aumentando a acurácia dos resultados.
Modelos preditivos, quando bem estruturados, ajudam a antecipar riscos e oportunidades. Mas para que isso ocorra, é preciso algo ainda mais fundamental: bons inputs e pessoas letradas em IA. Trabalhar em um mundo pós-IA generativa não se resume a criar bons prompts ou dominar ferramentas. É entender que os modelos refletem os dados que recebem: se a entrada é confusa, enviesada ou desorganizada, a saída também será. Em essência, a inteligência artificial é uma tecnologia de tradução de informações, e seu uso exige responsabilidade e senso crítico sobre os dados que alimentam o sistema.
Por isso, organizar informações de forma consciente, estruturada e ética é talvez o maior desafio — e o maior diferencial competitivo — das organizações nos próximos anos. A assertividade dos modelos nasce da qualidade dos inputs. E a maturidade digital será medida, cada vez mais, pela capacidade de compreender, proteger e valorizar os próprios dados. Dados abertos e externos estão disponíveis a todos, mas os que as organizações geram e têm o privilégio de acessar serão seu verdadeiro diferencial. Um dado pode até existir, mas só se torna valioso quando está organizado e pronto para ser processado.
| Para ter acesso às referências desse texto clique aqui. |
Quem publicou esta coluna
Lucas Tangi




























